OpenClaw系列第3.5课:先学会 openclaw gateway status,你就知道系统到底活没活

OpenClaw系列第3.5课:先学会 openclaw gateway status,你就知道系统到底活没活
Kai这是「OpenClaw 教程课程」第 3.5 课。
它是第 3 课 Gateway 原理篇之后的一节实操补充课。你可以把它理解成:Gateway 排查入门。
图:很多 OpenClaw 的问题,表面看像模型或渠道问题,本质上第一步都该先检查 Gateway 状态。
很多新手装完 OpenClaw 后,最常见的几种困惑是:
- 我明明装好了,为什么不回消息?
- 是模型挂了,还是 Gateway 没起来?
- Dashboard 打不开,到底先查哪里?
- 现在应该重启,还是先别乱动?
这时候,最值得你先学会的,不是什么复杂配置,也不是马上去研究 Session、Bindings 或 Tool Policy。
而是一个特别基础、但特别值钱的命令:
1 | openclaw gateway status |
今天这篇文章,就只讲这个。
一、为什么要先学这个命令?
因为 OpenClaw 能不能正常工作,核心前提是:
Gateway 正在运行,而且真的可用。
你可以把 Gateway 理解成 OpenClaw 的总控台,它负责:
- 收消息
- 做路由
- 调 Agent
- 调工具
- 回传结果
- 维护控制平面
所以只要 OpenClaw 哪里不对,第一步先看 Gateway 状态,几乎总是比盲猜更有效。
换句话说:
gateway status不是一个普通命令,它是排错入口。
二、最小可运行示例
你先记住最基础的一条:
1 | openclaw gateway status |
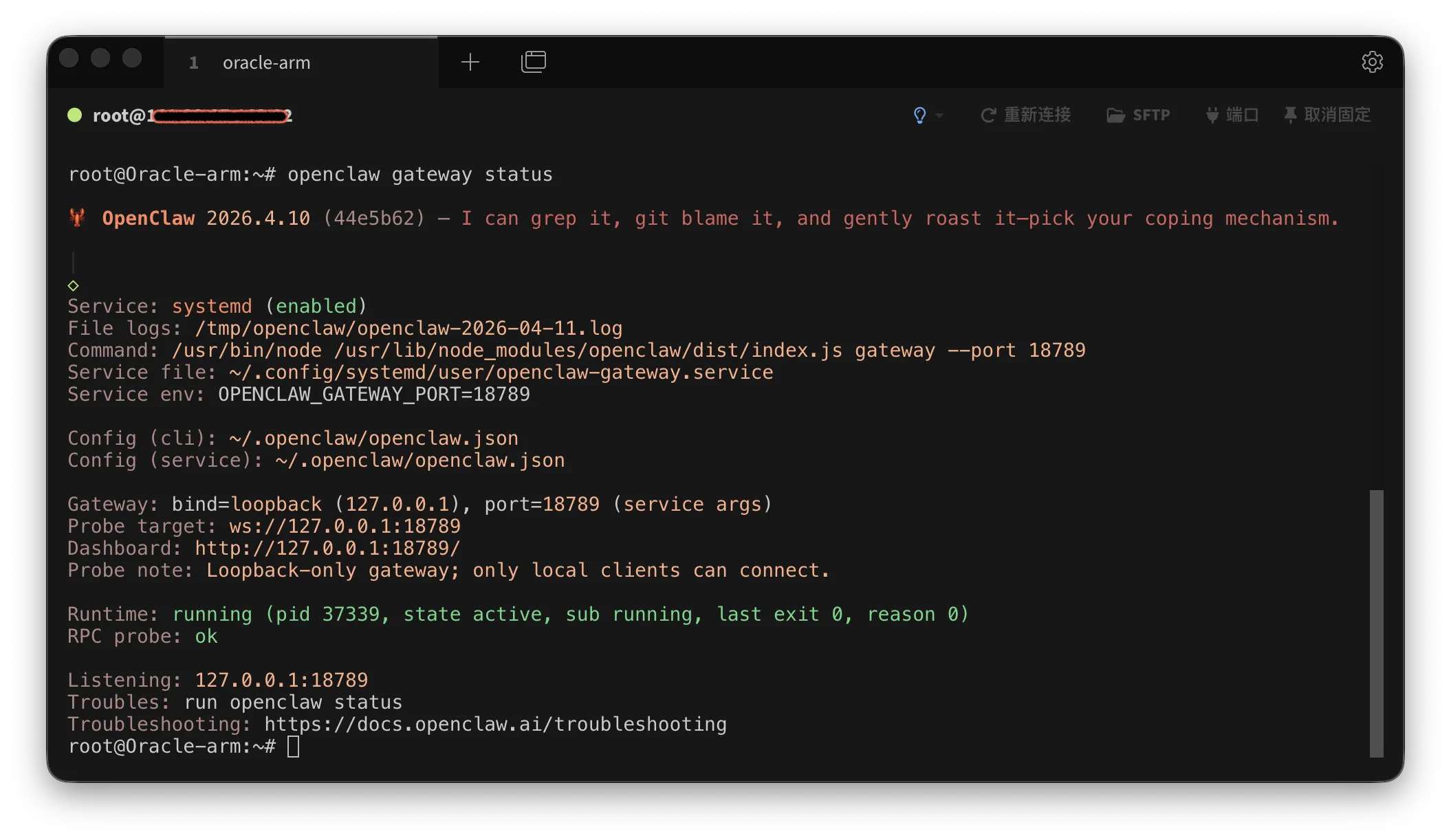
如果你想更严格一点地确认 Gateway 是否真的能响应,而不只是“进程看起来还在”,可以进一步记住:
1 | openclaw gateway status --json |
其中:
status:最常用,先看总状态status --json:适合脚本、结构化查看status --deep:适合怀疑系统里还有其他旧服务、残留服务、多实例冲突时排查
三、为什么 status 值得先看,而不是先 restart?
很多新手一发现不回消息,第一反应是:
1 | openclaw gateway restart |
这不是完全错,但顺序不够好。
更好的顺序是:
- 先看
gateway status - 看清楚 Gateway 现在是什么状态
- 再决定要不要 restart
为什么?
因为这两件事解决的是不同问题:
gateway status 解决的是“确认现状”
它回答的是:
- Gateway 在不在?
- 现在是不是 running?
- RPC 是否可达?
- 服务是不是看起来正常?
gateway restart 解决的是“尝试恢复”
它回答的是:
- 既然现在状态不对,我把它重新拉起来试试
如果你一上来就 restart,你会直接失去很多判断线索。
所以更专业的习惯是:
先 status,再决定要不要 restart。
四、gateway status 到底在看什么?
很多人会误以为这个命令只是在看:
- 进程在不在
其实不止。
从当前文档能看出来,它关注的是两层:
1)Runtime / 服务层
也就是 Gateway 这个核心服务有没有真的在运行。
2)RPC probe / 可达性层
也就是:
它不只是“活着”,而且还能正常响应。
这点非常关键。
因为在实际环境里,经常会出现一种情况:
- 进程还在
- 但服务已经不正常了
- 或者端口状态异常
- 或者控制平面不可达
所以“看起来在”不等于“真的可用”。
这就是为什么 gateway status 的价值这么大。
五、一个很实用的判断习惯:先分清“运行着”和“可用”
你以后排查时,脑子里要先拆成这两个问题:
问题 1:Gateway 运行着吗?
这是最基础的服务状态问题。
问题 2:Gateway 可用吗?
这是更关键的服务质量问题。
也就是说,你不要只满足于:
- “它大概还在吧”
而要进一步确认:
- “它现在是不是能正常接收控制请求、正常响应状态探测?”
这是从“会用命令”走向“会排错”的第一步。
六、什么时候该用 --deep?
一般情况下,先用:
1 | openclaw gateway status |
就够了。
但有一些情况,你应该进一步用:
1 | openclaw gateway status --deep |
比如:
- 你怀疑系统里还有旧的 Gateway 服务残留
- 你改过安装方式或运行方式
- 你觉得当前 CLI 指向的服务和你实际跑的不是同一个
- 你在一台机器上做过多实例测试
- 你怀疑 launchd / systemd / 旧服务配置有冲突
--deep 的意义不是“普通状态更详细一点”,而更像是:
做一次更深层的服务扫描。
这个参数特别适合那些“看起来怪怪的、但又说不清哪不对”的场景。
七、什么时候该用 --json?
如果你是自己肉眼看状态,普通的:
1 | openclaw gateway status |
通常就够了。
但以下情况更适合:
1 | openclaw gateway status --json |
1)你想把结果交给脚本处理
比如:
- 自检脚本
- 定时健康检查脚本
- 自动通知脚本
2)你想更稳定地读取字段
因为结构化输出比纯文本更适合后续处理。
3)你想做自己的运维观察面板
这时 JSON 输出会更友好。
所以你可以把 --json 理解成:
给机器看的版本。
八、实际排查时,一个很稳的顺序是什么?
这里给你一套非常实用的最小顺序。
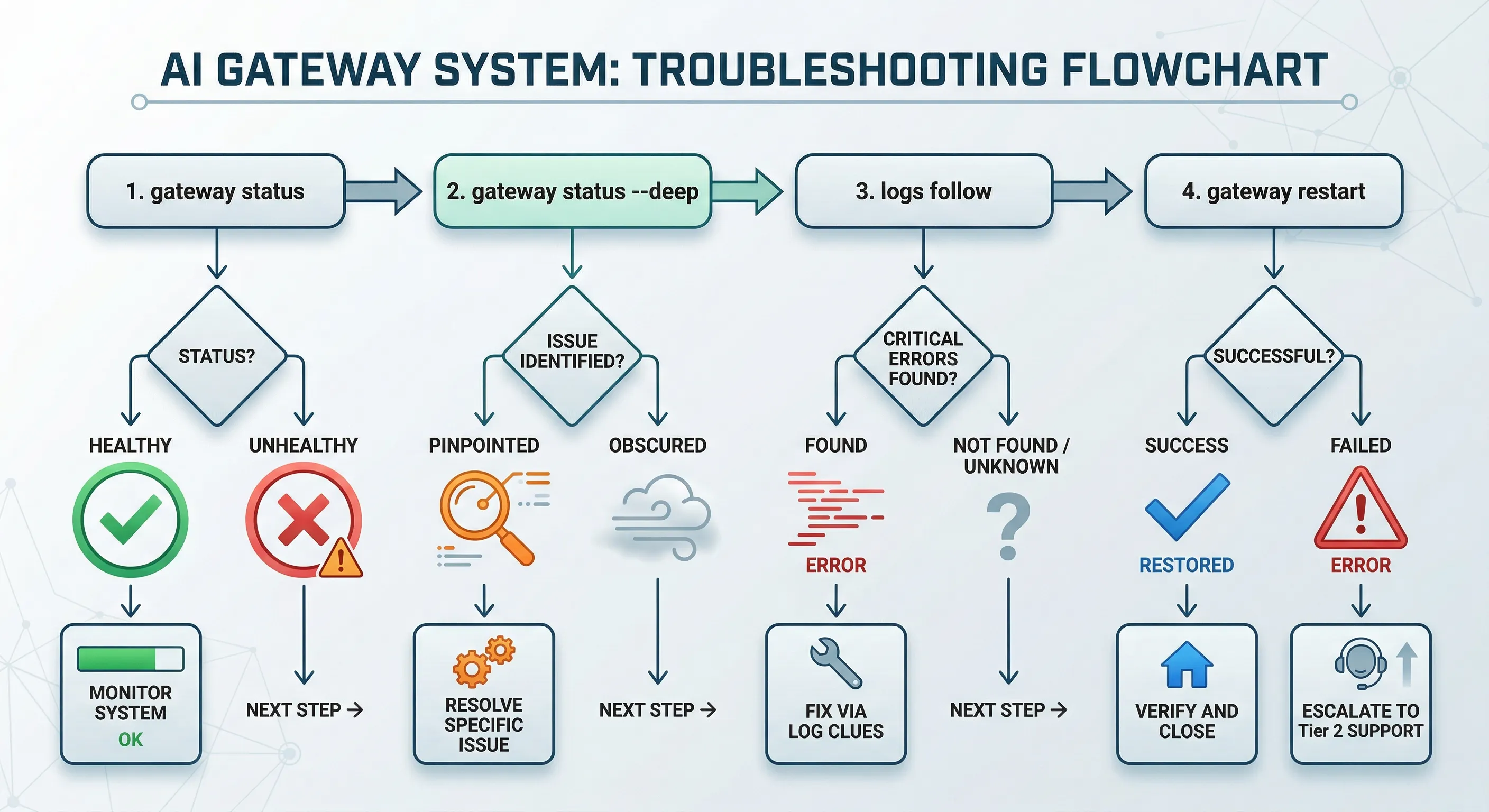
假设你现在发现:
- OpenClaw 不回消息
- Dashboard 打不开
- 工具调用没反应
请先按下面这套顺序来:
第一步:先看状态
1 | openclaw gateway status |
第二步:如果觉得不对,再看深一点
1 | openclaw gateway status --deep |
第三步:必要时看日志
1 | openclaw logs --follow |
第四步:确认问题后再决定要不要 restart
1 | openclaw gateway restart |
这套顺序的重点是:
先看,再判断,再处理。
不要一上来就重启,更不要一上来就怀疑模型。
九、最常见的几个误区
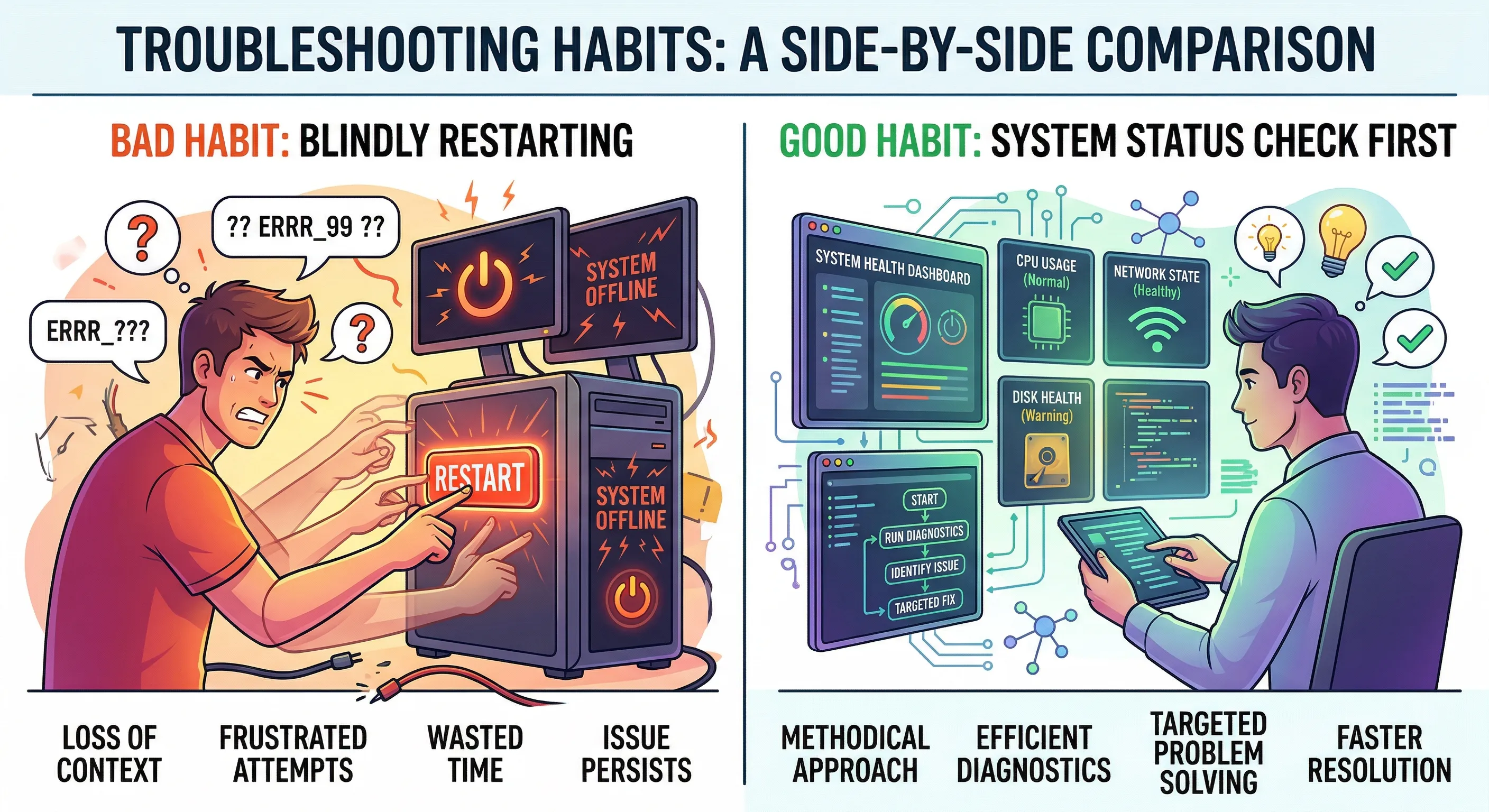
误区 1:服务 running,就等于一切正常
不一定。
running 只是说明它“看起来活着”。
但你真正关心的是:
- 它现在能不能正常响应
- 控制平面是不是通的
- 这是不是你当前该连的那个 Gateway
所以不要只满足于“它还在”。
误区 2:消息没回,先怪模型
这也是很常见的新手误区。
实际上,很多时候问题根本不在模型,而在:
- Gateway 没起来
- Gateway 可达性异常
- 服务配置漂移
- 旧服务冲突
所以你以后遇到“不回复”,先问自己一句:
Gateway 状态我看了吗?
误区 3:restart 是万能药
也不是。
restart 有用,但它只是恢复动作,不是分析动作。
如果你总是一上来就 restart,你会越来越依赖碰运气,而不是建立真正的排查能力。
十、你今天最值得收藏的命令组合
如果你今天只想记住最有用的一组,我建议记下面这 4 条:
1 | openclaw gateway status |
它们分别对应:
- 看基础状态
- 看更深层服务情况
- 给脚本或结构化读取用
- 必要时尝试恢复
十一、这节课最重要的一句话
如果今天这篇你只记住一句话,那就记住这句:
openclaw gateway status是 OpenClaw 排错的第一入口。
不是因为它最复杂,恰恰是因为它最基础、最关键。
你以后越往后学:
- 渠道接入
- Session
- Tool
- Cron
- Node
- Dashboard
你越会发现:
很多问题最后第一步都绕不开它。
十二、总结
这节课你只要真正记住下面 4 件事,就够了:
- Gateway 是 OpenClaw 的核心服务。
openclaw gateway status是最先该学会的排查命令。- 先 status,再决定要不要 restart。
- “进程在”不等于“系统真的可用”。
下一课预告
下一课我们会回到课程第 4 课:
怎么把 Telegram / Signal / Discord 接进来
也就是开始真正接入聊天渠道,让 OpenClaw 从本地面板走向“能在消息软件里用”。
🦞 本文由八条撰写,持续更新中。